Essay
Voice Agents: The Hard Problems Nobody Warns You About
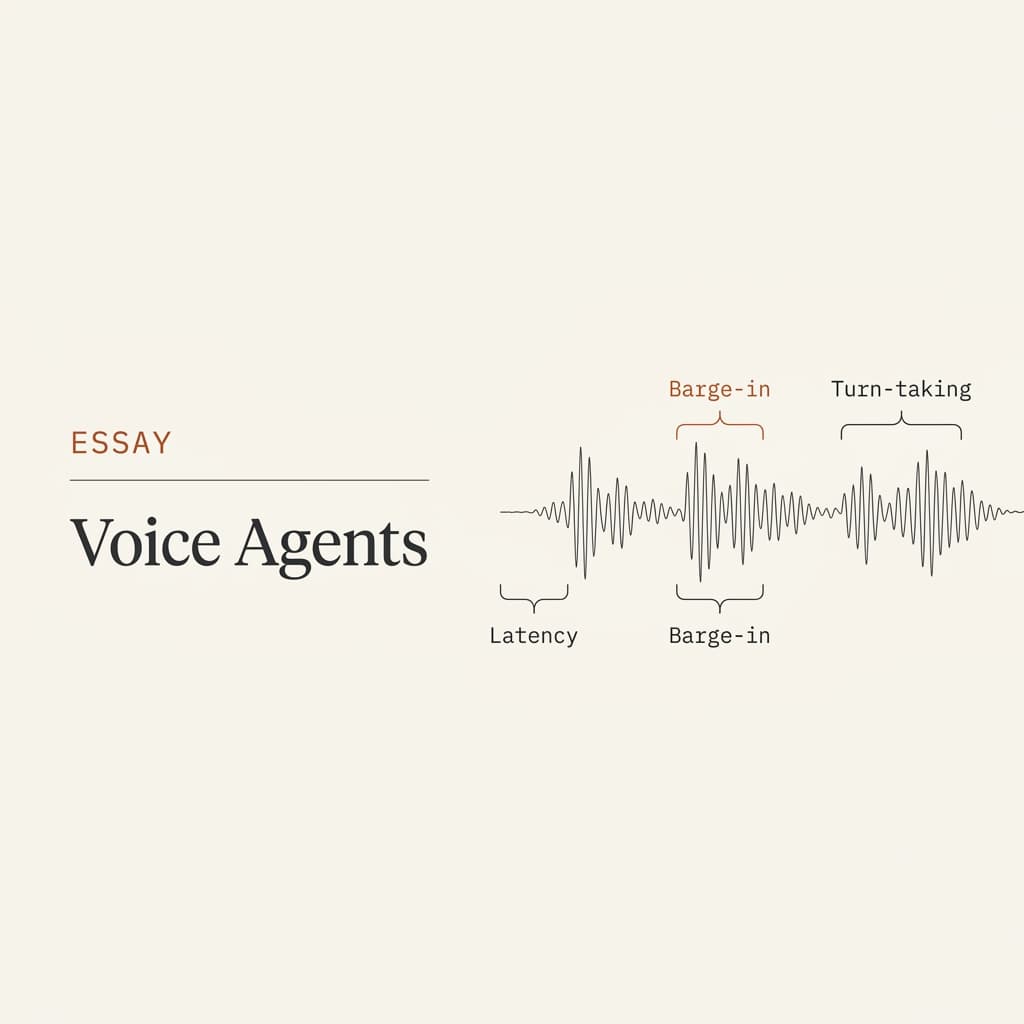
The demo is easy — speech-to-text, LLM, text-to-speech, done. Then a real person talks to it and everything falls apart: the silences are too long, it talks over them, it can't tell when they're done. The hard problems in voice aren't the models. They're latency, barge-in, and turn-taking.
The voice agent demo takes an afternoon. Microphone → speech-to-text → LLM → text-to-speech → speaker. Wire four boxes together and it talks back. It feels like you've solved voice.
Then you hand it to a human, and the human does human things — pauses mid-sentence to think, interrupts, says "uh" — and the whole thing falls apart. Not because a model is wrong, but because conversation is a real-time system with brutal timing constraints, and the naive pipeline honors none of them.
I've spent enough time on this to have opinions. The models are the easy part. Here are the three problems that actually decide whether a voice agent feels human or feels broken.
None of this is about which STT or LLM you pick. It's about the timing between them. You can have the best models in the world and a voice agent that feels awful because the milliseconds are wrong.
Problem 1: Latency — the 236ms you don't have
In text chat, a two-second wait is fine — you watch tokens stream and feel progress. In voice, there's no progress bar. There's just silence, and humans read silence as the other person didn't understand me within about a quarter-second. Research on conversation puts the average gap between turns around 200ms. Miss that and every exchange feels like a bad phone call on a satellite delay.
The trap is that the naive pipeline is sequential: each stage waits for the previous one to fully finish. Add up the boxes and you're nowhere near 200ms.
The fix is to stop waiting for "full." Stream partial transcripts out of STT before the user stops talking, stream the LLM token-by-token, and start synthesizing speech from the first sentence while the model is still writing the second. The user hears audio starting ~450ms after they stop — not 1,700ms — because the stages overlap instead of queue.
The single highest-leverage move: start TTS on the first sentence boundary, not the full LLM response. The model can still be generating paragraph three while the user is already hearing paragraph one. Sentence-chunked TTS is what collapses perceived latency more than any model swap.
Problem 2: Barge-in — letting them interrupt
Real conversation is interruptible. You start explaining, the other person gets it halfway through and says "yep, got it" — and you stop. A voice agent that plows through its full scripted answer while the user is actively talking over it feels less like a person and more like an IVR phone tree, and people hate it with a specific intensity.
Barge-in means: while the agent is speaking, keep the mic hot, keep running STT, and the instant real speech is detected — kill the current TTS playback, flush the queued audio, and listen. That last part trips people up: it's not enough to stop generating; you have to drop the audio already buffered on the client, or the agent keeps talking for a second after it should've stopped.
The hard sub-problem hiding inside barge-in: telling a real interruption from a backchannel. "Mm-hm" and "right" and "yeah" aren't interruptions — they're the listener signaling keep going. An agent that halts every time you say "uh-huh" is as broken as one that never stops. You need voice-activity detection tuned to distinguish a genuine turn-grab from an encouraging noise, and it's genuinely hard to get right.
Problem 3: Turn-taking — knowing when they're done
This is the deepest one. When the user goes quiet, are they finished, or just thinking? Get it wrong in one direction and the agent interrupts them mid-thought. Get it wrong in the other and there's an awkward two-second void before it responds. Humans negotiate this constantly and invisibly, using prosody — falling pitch, slowing pace, grammatical completeness — none of which a naive "wait for 700ms of silence" timer can hear.
The naive approach is a fixed silence threshold, and it's wrong in both directions at once:
The real fix is semantic end-of-turn detection: a model that judges whether the utterance is complete — grammatically and in intonation — not merely whether some milliseconds of silence elapsed. "I want to book a flight to…" [pause] is obviously unfinished even after a long silence; "I want to book a flight to Lisbon." is finished the instant the period lands. Duration is a proxy; completeness is the actual signal.
How the SDKs help — and where they stop
Frameworks like Mastra's voice layer give you the plumbing: a voice provider
with speak(), listen(), and a real-time connect() / send() / on()
event model, plus CompositeVoice to mix providers (one vendor's STT, another's
TTS). That's real leverage — you're not hand-rolling audio transport.
import { Agent } from "@mastra/core/agent";
import { OpenAIVoice } from "@mastra/voice-openai";
const agent = new Agent({
name: "concierge",
instructions: "You are a warm, concise phone concierge. Keep answers short — this is spoken, not read.",
model: openai("gpt-4o"),
voice: new OpenAIVoice(),
});
// Real-time, event-driven — the shape that makes barge-in possible.
await agent.voice.connect();
agent.voice.on("speaking", (audio) => playToSpeaker(audio));
agent.voice.on("writing", (text) => appendTranscript(text));
agent.voice.send(micStream); // stream mic audio in continuouslyNotice the instruction: "Keep answers short — this is spoken, not read." A voice agent that returns three paragraphs is wrong even if every word is correct, because nobody wants a paragraph read aloud at them. Writing for the ear is its own discipline the SDK can't do for you.
But the SDK gives you the transport, not the timing. The event model
(connect/send/on) is what makes low latency and barge-in possible —
streaming in, streaming out, interruptible. Whether your agent actually feels
good still comes down to the three problems above: how fast you start speaking,
how fast you stop when interrupted, and how well you judge when the human is
done. Those are yours to solve.
The uncomfortable takeaway
Every hard problem in voice is a timing problem, not a model problem. You could freeze the models exactly where they are today and still make voice agents dramatically better purely by fixing latency, barge-in, and turn-taking. And you could have next year's models and still ship something people hang up on if you get the milliseconds wrong.
That's the part the afternoon demo hides. Wiring the four boxes together is the easy 20%. Making the silences the right length is the other 80% — and it's the only part the user actually feels.
If you're building the agent underneath the voice, my Mastra series covers the loop, tools, and streaming that a voice layer sits on top of.